



















圖解大模型:生成式AI原理與實戰
作者: (沙烏地阿拉伯)傑伊‧阿拉馬爾,(荷)馬爾滕‧格魯滕多斯特
出版社:人民郵電出版社
出版日期:2025/05/01
開本:16開
頁碼:349
編輯推薦
【直覺】300幅全彩插圖,很好視覺化呈現
【全面】涵蓋大模型原理、應用開發、最佳化
【實操】真實資料集,實用項目,典型場景
【熱點】18幅圖深度解讀DeepSeek底層原理
【附贈】一鍵運行程式碼+大模型面試題200問
【影片】大量線上拓展資料,包括文章、視頻
內容介紹
本書全程圖解式講解,透過大量全彩插圖拆解概念,讓讀者真正告別學習大模型的枯燥與複雜。
全書分為三部分,依序介紹語言模型的原理、應用及最佳化。第一部分 理解語言模型(第1~3章),解析語言模型的核心概念,包括詞元、嵌入向量及Transformer架構,幫助讀者建立基礎認知。第二部分 使用預訓練語言模型(第4~9章),介紹如何運用大模型進行文本分類、聚類、語意搜尋、文本生成及多模態擴展,提升模型的應用能力。第三部分 訓練與微調語言模型(第10~12章),探討大模型的訓練與微調方法,包括嵌入模型的建構、分類任務的最佳化及生成式模型的微調,以適應特定需求。
本書適合對大模型有興趣的開發者、研究人員和產業從業人員。讀者無須深度學習基礎,只要會用Python,就可以透過本書深入理解大模型的原理並上手大模型應用開發。書中範例還可以一鍵在線上運行,讓學習過程更輕鬆。
作者介紹
(沙特)傑伊·阿拉馬爾(Jay Alammar),(荷)馬爾滕·格魯滕多斯特(Maarten Grootendorst) 著 李博傑 譯
Jay Alammar Cohere總監兼工程研究員,知名大模型技術部落格Language Models & Co作者,DeepLearning.AI和Udacity熱門機器學習和自然語言處理課程作者。 Jay的圖解系列文章「The Illustrated Transformer」「The Illustrated DeepSeek-R1」全網瘋傳,累積了數百萬專業讀者。 Maarten Grootendorst IKNL(荷蘭綜合癌症中心)高級臨床資料科學家,知名大模型技術部落格部落客,BERTopic等開源大模型軟體包作者( 量超百萬),DeepLearning.AI和Udacity熱門...
目錄
對本書的讚譽xi
對本書中文版的讚譽xiii
譯者序xv
中文版序xxi
前言xxiii
第一部分理解語言模型
第1章大語言模型簡介3
1.1什麼是語言人工智慧4
1.2語言人工智慧的近期發展史4
1.2.1將語言表示為詞袋模型5
1.2.2用稠密向量嵌入得到更好的表示7
1.2.3嵌入的類型9
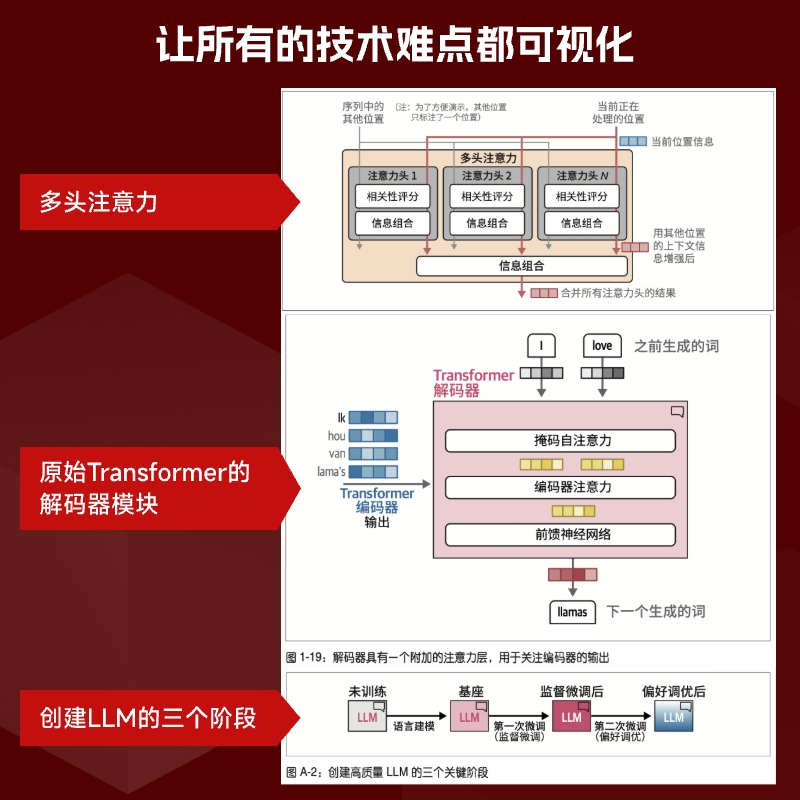
1.2.4使用注意力機制編解碼上下文10
1.2.5“Attention Is All You Need”13
1.2.6表示模型:僅編碼器模型16
1.2.7生成模型:僅解碼器模型18
1.2.8生成式AI元年20
1.3“LLM”定義的演變22
1.4LLM的訓練範式22
1.5LLM的應用23
1.6開發和使用負責任的LLM24
1.7有限的資源就夠了25
1.8與LLM交互25
1.8.1專有模型26
1.8.2開源模型26
1.8.3開源框架27
1.9生成你的第一段文字28
1.10小結30
第2章詞元與嵌入31
2.1LLM的分詞32
2.1.1分詞器如何處理語言模型的輸入32
2.1.2 和運行LLM33
2.1.3分詞器如何分解文本36
2.1.4詞級、子詞級、字元級與位元組級分詞37
2.1.5比較訓練好的LLM分詞器39
2.1.6分詞器屬性47
2.2詞元嵌入48
2.2.1語言模型為其分詞器的詞表保存嵌入49
2.2.2使用語言模型創建與上下文相關的詞嵌入49
2.3文本嵌入(用於句子和整篇文檔)52
2.4LLM之外的字嵌入53
2.4.1使用預訓練詞嵌入53
2.4.2word2vec演算法與對照訓練54
2.5推薦系統中的嵌入57
2.5.1基於嵌入的歌曲推薦57
2.5.2訓練歌曲嵌入模型58
2.6小結60
第3章LLM的內部機制61
3.1Transformer模型概述62
3.1.1已訓練TransformerLLM的輸入與輸出62
3.1.2前向傳播的組成64
3.1.3從機率分佈中選擇單一詞元(取樣/解碼)66
3.1.4並行詞元處理與上下文長度68
3.1.5透過快取鍵值加速生成過程70
3.1.6Transformer塊的內部結構71
3.2Transformer架構的近期新改進79
3.2.1更有效率的注意力機制79
3.2.2Transformer塊83
3.2.3位置嵌入:RoPE85
3.2.4其他架構實驗和改進87
3.3小結87
第二部分使用預訓練語言模型
第4章文本分類91
4.1電影評論的情緒分析92
4.2使用表示模型進行文本分類93
4.3模型選擇94
4.4使用特定任務模型96
4.5利用嵌入向量的分類任務99
4.5.1監督分類99
4.5.2沒有標註數據怎麼辦102
4.6使用生成模型進行文本分類105
4.6.1使用T5106
4.6.2使用ChatGPT進行分類110
4.7小結113
第5章文本聚類與主題建模114
5.1ArXiv文章:計算與語言115
5.2文本聚類的通用流程116
5.2.1嵌入文檔116
5.2.2嵌入向量降維117
5.2.3對降維後的嵌入向量進行聚類119
5.2.4檢查產生的簇120
5.3從文本聚類到主題建模122
5.3.1BERTopic:一個模組化主題建模架構124
5.3.2添加特殊的「樂高積木塊」131
5.3.3文本生成的「樂高積木塊」135
5.4小結138
第6章提示工程140
6.1使用文本生成模型140
6.1.1選擇文本生成模型140
6.1.2載入文本生成模型141
6.1.3控制模型輸出143
6.2提示工程簡介145
6.2.1提示詞的基本要素145
6.2.2基於指令的提示詞147
6.3高級提示工程149
6.3.1提示詞的潛在複雜性149
6.3.2上下文學習:提供範例152
6.3.3鍊式提示:分解問題153
6.4使用生成模型進行推理155
6.4.1思維鏈:先思考再回答156
6.4.2自洽性:取樣輸出159
6.4.3思維樹:探索中間步驟160
6.5輸出驗證161
6.5.1提供範例162
6.5.2語法:約束採樣164
6.6小結167
第7章高級文本生成技術與工具168
7.1模型輸入/輸出:基於LangChain負載量化模型169
7.2鏈:擴展LLM的能力171
7.2.1鍊式架構的關鍵節點:提示詞模板172
7.2.2多提示詞鍊式架構174
7.3記憶:建構LLM的對話回溯能力177
7.3.1對話緩衝區178
7.3.2視窗式對話緩衝區180
7.3.3對話摘要181
7.4智能體:建構LLM系統185
7.4.1智能體的核心機制:遞進式推理186
7.4.2LangChain中的ReAct實作187
7.5小結190
第8章語意搜尋與RAG191
8.1語意搜尋與RAG技術全景191
8.2語言模型驅動的語意搜尋實踐193
8.2.1稠密檢索193
8.2.2重排序204
8.2.3檢索評估指標系統207
8.3RAG211
8.3.1從搜尋到RAG212
8.3.2範例:使用LLMAPI進行基於知識的生成213
8.3.3範例:使用本地模型的RAG213
8.3.4高級RAG技術215
8.3.5RAG效果評估217
8.4小結218
第9章多模態LLM219
9.1視覺Transformer220
9.2多模態嵌入模型222
9.2.1CLIP:建構跨模態橋樑224
9.2.2CLIP的跨模態嵌入生成機制224
9.2.3OpenCLIP226
9.3讓文本生成模型具備多模態能力231
9.3.1BLIP-2:跨越模態鴻溝231
9.3.2多模態輸入預處理235
9.3.3用例1:圖像描述237
9.3.4用例2:基於聊天的多模態提示詞240
9.4小結242
第三部分訓練與微調語言模型
第10章建構文本嵌入模型247
10.1嵌入模型247
10.2什麼是對比學習249
10.3SBERT251
10.4建構嵌入模型253
10.4.1產生對比樣本253
10.4.2訓練模型254
10.4.3深入評估257
10.4.4損失函數258
10.5微調嵌入模型265
10.5.1監督學習265
10.5.2增強型SBERT267
10.6無監督學習271
10.6.1TSDAE272
10.6.2使用TSDAE進行領域適配275
10.7小結276
第11章為分類任務微調表示模型277
11.1監督分類277
11.1.1微調預訓練的BERT模型279
11.1.2凍結層281
11.2少樣本分類286
11.2.1SetFit:少樣本場景下的高效微調方案286
11.2.2少樣本分類的微調290
11.3基於掩碼語言建模的繼續預訓練292
11.4命名實體識別297
11.4.1資料準備298
11.4.2命名實體辨識的微調303
11.5小結305
第12章微調生成模型306
12.1LLM訓練三步驟:預訓練、監督微調與偏好調優306
12.2監督微調308
12.2.1全量微調308
12.2.2參數高效能微調309
12.3使用QLoRA進行指令微調317
12.3.1模板化指令資料317
12.3.2模型量化318
12.3.3LoRA配置319
12.3.4訓練配置320
12.3.5訓練321
12.3.6合併權重322
12.4評估生成模型322
12.4.1詞級指標323
12.4.2基準測試323
12.4.3排行榜324
12.4.4自動評估325
12.4.5人工評估325
12.5偏好調優、對齊326
12.6使用獎勵模型實現偏好評估自動化327
12.6.1獎勵模型的輸入與輸出328
12.6.2訓練獎勵模型329
12.6.3訓練無獎勵模型332
12.7使用DPO進行偏好調優333
12.7.1對齊資料的模板化333
12.7.2模型量化334
12.7.3訓練配置335
12.7.4訓練336
12.8小結337
附錄圖解DeepSeek-R1338
後記349
從零構建大模型
ISBN13:9787115666000
出版社:人民郵電出版社
作者:(美)塞巴斯蒂安‧拉施卡
出版日:2025/04/01
裝訂/頁數:平裝/325頁
規格:24cm*17cm (高/寬)
版次:一版
編輯推薦
Github4萬星神作,資料處理+模型搭建+無監督訓練+任務微調,僅需掌握Python,帶你從零構建AI大模型; 揭開大模型背後的面紗,讓讀者了解其工作原理,學習如何評估其質量,並掌握微調和改進的具體技術;強調親手實踐,使用PyTorch 而不依賴於解庫,透過微調和改進的具體技術;透過本書的學習,讀者可以創建自己的小型但功能強大的模型,並將其作為個人助手使用; 更有驚喜彩蛋:深度解析DeepSeek大模型背後技術,揭秘行業前沿!
內容介紹
本書是關於如何從零開始建立大模型的指南,由暢銷書作家塞巴斯蒂安·拉施卡撰寫,透過清晰的文字、圖表和實例,逐步指導讀者創建自己的大模型。在本書中,讀者將學習如何規劃和編寫大模型的各個組成部分、為大模型訓練準備適當的資料集、進行通用語料庫的預訓練,以及自訂特定任務的微調。此外,本書也將探討如何利用人工回饋確保大模型遵循指令,以及如何將預訓練權重載入到大模型中。
本書適合對機器學習和生成式AI感興趣的讀者閱讀,特別是那些希望從零開始建立自己的大模型的讀者。
作者介紹
(美)塞巴斯蒂安·拉施卡(Sebastian Raschka) 著 覃立波,馮驍騁,劉乾 譯
塞巴斯蒂安·拉施卡(Sebastian Raschka),極具影響力的人工智慧專家,本書配套GitHub專案LLMs-from-scratch達4萬顆星。現在大模型獨角獸公司Lightning Al任資深研究工程師。博士畢業於密西根州立大學,2018~2023年威斯康辛大學麥迪遜分校助理教授(終身教職),從事深度學習研究與教學。除本書外,他還寫了暢銷書《大模型技術30講》和《Python機器學習》。 【譯者簡介】 覃立波,中南大學特聘教授,博士生導師。現任中國中文資訊學會青工委秘書長。主要研究興趣為人工智慧、自然語言處理、大模型等。曾擔任ACL.EMNLP、NAACL、IJCAI等國際會議...
目錄
第1章理解大語言模型1
1.1什麼是大語言模型2
1.2大語言模型的應用3
1.3建構和使用大語言模型的各個階段4
1.4Transformer架構介紹6
1.5利用大型資料集9
1.6深入剖析GPT架構11
1.7建構大語言模型13
1.8小結14
第2章處理文字資料15
2.1理解詞嵌入16
2.2文本分詞18
2.3將詞元轉換為詞元ID21
2.4引入特殊上下文詞元25
2.5BPE29
2.6使用滑動視窗進行資料採樣31
2.7創建詞元嵌入37
2.8編碼單字位置資訊40
2.9小結44
第3章編碼注意力機制45
……

